Invoice/Finance OCR Pipeline
An automated email-to-P&L workflow replacing manual invoice processing for small finance teams
TL;DR
Tincture built an automated invoice OCR pipeline that replaces manual finance processing for small businesses, taking incoming supplier invoice emails through OCR extraction, vendor and category classification, approval routing, and structured database entry, with real-time P&L sync. The pattern runs on standard tooling ([Relay.app](http://Relay.app) or n8n for orchestration, Google Apps Script/Custom Functions for currency calculations, OCR APIs for extraction, Notion and/or Google Sheets for storage and reporting) and applies wherever a small team is processing more invoices than headcount justifies. Originally built inside a start-up’s operating-system engagement, productized as a transferable pattern for any early-stage business outgrowing manual finance processing.
The brief
What did the client need?
Most small businesses with operational complexity above their headcount end up with a finance bottleneck shaped like this: invoices arrive by email, somebody opens each one, types the line items into a spreadsheet, categorises by vendor and type, routes for approval, files the invoice, and updates the P&L. The work is high-volume, low-judgement, error-prone, and recurring. It's the most automatable workflow in any small business, and almost nobody automates it.
The category has standard solutions (Xero, QuickBooks, FreshBooks) but they sit awkwardly between automation and accounting. They handle the books once the invoice is structured; they don't handle the structuring. The team still types the line items in.
The brief was a pipeline that does the structuring automatically: invoice arrives, system reads it, extracts the line items, categorises, routes for approval, enters into the structured store, syncs to the P&L surface. End-to-end with zero manual data entry on the standard path.
The constraints
What made this hard?
Three constraints. The first was OCR reliability across formats. Invoices arrive as PDF attachments (sometimes typed, sometimes scanned), as inline email body text, as Word documents, occasionally as photos. OCR works well on clean PDFs and badly on photos of crumpled receipts. The pipeline had to handle the easy cases at scale and route the hard cases to human review without breaking.
The second was vendor and category classification. The same supplier can show up with three different name variants on different invoices. The pipeline had to normalise vendor names and apply consistent category mapping across invoices, otherwise the P&L ends up with "Acme Corp", "Acme", and "ACME LTD" as three different vendors. That kind of fuzziness is what turns a clean P&L into reconciliation work.
The third was approval routing. Small businesses don't have rigid approval matrices, but they do have rules ("anything over $1k goes to the founder", "supplier X auto-approves", "first invoice from a new vendor gets reviewed"). The pipeline needed configurable routing logic that respects those rules without hardcoding assumptions.
The approach
How did Tincture frame the problem?
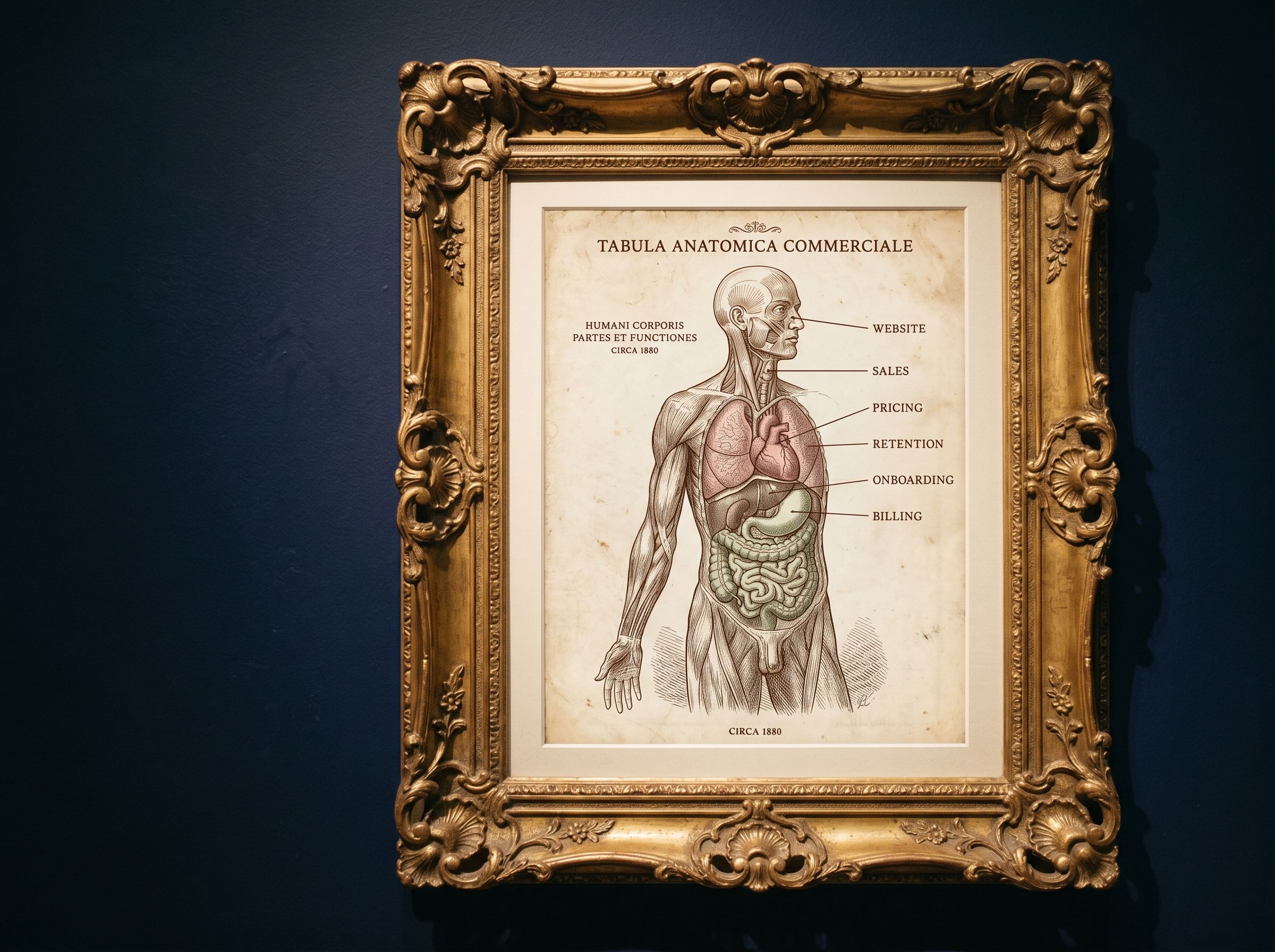
A linear pipeline triggered by incoming email, with clean handoffs between stages: OCR extraction, vendor and category classification, approval routing, structured storage, P&L sync. Each stage scoped to its specific job, with explicit failure modes when the stage can't complete.
OCR extraction runs first, against the email attachment or body. Output is structured line items: vendor (raw), date, items, amounts, taxes, total. Confidence scores per field, so the pipeline knows when to escalate.
Vendor and category classification runs second, against the OCR output. Vendor normalisation against a canonical list (with fuzzy matching). Category assignment against a chart of accounts. New vendors flagged for human approval before they enter the canonical list.
Approval routing runs third, against the classified invoice. Configurable rules per business: amount thresholds, vendor whitelists, category-specific routes. Output is either an auto-approval or an approval task assigned to a human.
Structured storage runs fourth, into Notion or Google Sheets or Airtable. Approved invoices land in the structured store; rejected or pending invoices land in a review queue.
P&L sync runs last, pulling from the structured store into a real-time P&L surface. Margin per project, margin per quarter, vendor concentration, category distribution. The numbers live where commercial decisions get made.
The build
What was shipped?
A pipeline orchestrator (Relay.app for the original application; n8n or Make for other implementations) handling the stage transitions. OCR via standard APIs (Mindee, Adobe Acrobat, AWS Textract depending on the volume and accuracy profile required).
A vendor canonical list and chart of accounts maintained per implementation, with fuzzy matching logic for vendor normalisation and category mapping rules. New vendor flow with human-in-the-loop approval for first invoices.
Approval routing logic configured per business, covering amount thresholds, vendor-specific rules, and category routing. Output is either auto-approval (most invoices on the standard path) or an approval task for a human.
Structured storage in Notion (for the originating engagement) or Google Sheets / Airtable (for other applications), with relational links to projects, vendors, and categories. P&L sync into a Google Sheets or Notion view, refreshing on each new invoice approval.
A monitoring layer logging pipeline runs, OCR confidence scores, classification accuracy, and approval routing decisions, so the operator can see when the pipeline is misbehaving and what's getting escalated.
The outcome
What were the results?
For the start up application: invoice processing went from a manual line-item exercise to an email-and-approve flow, with the P&L updating in near-real-time. The finance team's monthly close got materially faster. The founders see margin per project, not margin per quarter.
The structural outcome is the generalisable pattern. The same pipeline architecture (OCR, classify, route, store, P&L sync) applies to any small business processing invoices above the headcount that justifies a finance hire. Different orchestrator, same architecture. Different OCR API, same architecture. Different storage substrate, same architecture.
The compounding outcome is the data quality. Once the canonical vendor list and the category mapping are stable, the P&L is clean. Reconciliation work goes from a monthly task to an exception flow. The hours that used to go into manual invoice entry go into commercial decisions instead.
What it took
What tools and methods were used?
The orchestrator layer: Relay.app for the originating engagement (chosen because the rest of that stack ran on Notion + Relay automation). n8n or Make for other implementations where the existing stack pointed differently. The orchestrator choice is a function of the existing stack; the architecture is invariant.
The OCR layer: standard APIs depending on volume and accuracy requirements. Mindee for invoice-specific extraction with structured output. Adobe Acrobat for PDFs at low volume. AWS Textract for scale. The pipeline abstracts the OCR provider so it can swap without restructuring downstream.
The classification layer: rule-based fuzzy matching for vendors, deterministic category mapping for accounts. ChatGPT API or Claude API for edge cases where rules fail. LLM cost stays small because the easy cases get pattern-matched first.
The methodological underpinning is the practice's pattern for finance automations: structured outputs, exception-flagged escalations, real-time P&L surfacing. Most attempts at finance automation try to replace the accounting layer (which is the wrong target). The right target is the data entry layer; once that's automated, the accounting tools work as designed.
The takeaway
What's the transferable principle?
Most small businesses underautomate finance because the available products (Xero, QuickBooks) sit on top of structured data, and the structuring is the actual work. The work that compounds is the pipeline that does the structuring; the accounting layer takes care of itself once the data is clean.
For the originating engagement, that meant Relay.app + OCR + Notion + Google Sheets. For a different business, the orchestrator and storage might change, but the architecture is the same: extract, classify, route, store, sync. The pattern works at any scale where invoice volume is above the headcount that justifies a finance hire and below the scale that justifies an enterprise ERP.
The other transferable principle, broader than invoices: automate the data entry, not the decision-making. The pipeline doesn't decide whether an invoice should be paid; it routes the decision to the right human with the right context. That distinction is what makes the automation safe to deploy in finance specifically, where mistakes are expensive and audit trails are non-negotiable.
Read more on this in SaaS Churn Rate Benchmarks: What Good Looks Like and How to Get There
Frequently asked questions


More like this
 Featured
Featured50–70 qualified leads projected in a four-week pilot, 5–8 likely to convert to warm conversations.
An AI opportunity engine for the London commercial demolition market
Tincture built an agentic signal-monitoring pipeline for a London commercial demolition contractor — aggregating insolvency notices, planning portals, derating registers, consultant pipelines, and vacancy data, interpreting them through an AI qualification layer tuned to the contractor's specific commercial profile, and delivering a weekly feed of actionable leads with outreach drafts pre-written. Based on live source volumes, a four-week pilot was projected to surface 50–70 qualified opportunities.

9,182 verified contacts from 30,001 ARB records, structured for direct CRM import.
An AI-assisted campaign-ready contact list for the entire UK architect market
Tincture processed the full UK Architects Registration Board register - 30,001 records — through five enrichment layers (Companies House, website discovery, email generation and selection, SMTP verification, and AI organisation classification) to produce a structured delivery pack with a 9,182-contact verified core send file ready for CRM import. The AI classification layer distinguished core architecture practices from in-house employers at scale, protecting the send list from bounce-rate risk.
 Featured
FeaturedPilot live by Tuesday. Anonymous collection with silent attribution working end-to-end.
A closed Q&A pilot built for AI analysis, live by Tuesday
Tincture helped a UK founder launch a closed Q&A pilot for their personal project — building anonymous response collection with silent participant attribution, structured for direct AI analysis per participant. The build ran on Vercel with a Supabase back-end, used unique URLs to carry participant identity without respondents ever identifying themselves, and delivered clean, typed response data ready to pass straight to an AI model. Pilot live by Tuesday, exactly as scoped.